„Crawlt Google meine Seite überhaupt noch?“, „Wie kommt mein Text in ChatGPT?“, „Und was passiert eigentlich beim Training einer KI?“ – diese drei Fragen hängen enger zusammen, als es auf den ersten Blick scheint. Denn hinter Suchmaschinen und KI-Antworten stecken drei sehr unterschiedliche Mechanismen, mit denen Maschinen an Ihre Inhalte kommen: das Crawling, die Echtzeit-Abfrage per RAG und das Training großer KI-Modelle. Wer versteht, wie diese drei Wege funktionieren, weiß auch, an welchen Stellschrauben er drehen muss, um in Google und in der KI sichtbar zu sein. Dieser Artikel erklärt alle drei – verständlich, technisch korrekt und mit konkreten Konsequenzen für Ihre Website.
Drei Wege, wie Maschinen an Ihre Inhalte kommen
Bevor wir in die Technik einsteigen, lohnt sich die große Landkarte. Ihre Website kann auf drei grundsätzlich verschiedene Arten von Maschinen erfasst werden:
- Crawling & Indexierung. Suchmaschinen wie Google und Bing – aber auch KI-Anbieter – schicken automatisierte Programme über das Web, die Seiten herunterladen, auswerten und in einen durchsuchbaren Index legen. Das ist die klassische Grundlage von SEO.
- Echtzeit-Abfrage (RAG). Wenn ChatGPT, Perplexity oder Google AI live im Netz nachschaut, um eine konkrete Frage zu beantworten, ruft das Modell einzelne Seiten in dem Moment ab, baut die relevanten Passagen in seinen Kontext ein und zitiert sie. Genau das meinen viele, wenn sie – nicht ganz korrekt – von „RAP“ sprechen. Der Fachbegriff lautet RAG: Retrieval-Augmented Generation.
- Training. Damit ein Sprachmodell überhaupt Sprache, Fakten und Zusammenhänge „kann“, wird es einmalig auf riesigen Textmengen trainiert. Was bis zum sogenannten Knowledge-Cutoff im Netz stand, kann Teil dieses Trainingswissens werden.
Diese drei Wege haben unterschiedliche Spielregeln. Wer sie verwechselt, optimiert an der falschen Stelle. Gehen wir sie der Reihe nach durch.
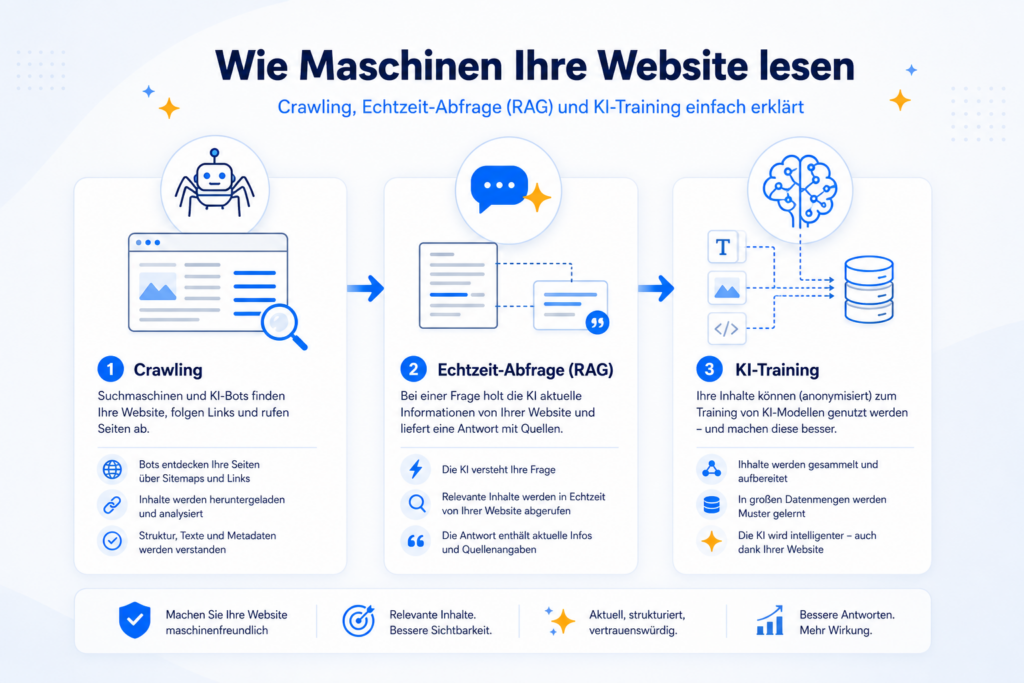
1. Wie funktioniert Crawling genau?
Ein Crawler (auch Spider oder Bot genannt) ist ein Programm, das automatisiert Webseiten besucht, ihren Inhalt herunterlädt und den darin enthaltenen Links folgt. Klingt simpel, ist in der Praxis aber ein hochgradig orchestrierter Prozess. Vereinfacht läuft er in diesen Schritten ab:
- URL-Warteschlange (Scheduler). Der Crawler führt eine gigantische Liste bekannter und neu entdeckter URLs. Aus dieser Warteschlange entscheidet ein Scheduler, welche Adresse als Nächstes – und wie oft – besucht wird.
- Abruf (Fetching). Der Bot stellt eine ganz normale HTTP-Anfrage an Ihren Server, so wie es ein Browser täte, und lädt den HTML-Code der Seite herunter. Dabei sendet er eine eindeutige Kennung mit, den
User-Agent(z. B.GooglebotoderGPTBot). - Regelprüfung (robots.txt). Vor dem Abruf prüft ein seriöser Crawler die Datei
robots.txtin Ihrem Wurzelverzeichnis. Dort legen Sie fest, welche Bereiche ein bestimmter Bot betreten darf und welche nicht. Hält sich ein Bot daran? Die großen, seriösen schon – aggressive Scraper ignorieren die Regeln oft. - Auswertung (Parsing). Aus dem heruntergeladenen Code extrahiert der Crawler den Textinhalt, Überschriften, Meta-Angaben, strukturierte Daten (Schema.org) und vor allem alle enthaltenen Links – die wiederum in die Warteschlange wandern.
- Rendering. Moderne Seiten bestehen oft nicht nur aus fertigem HTML, sondern bauen Inhalte erst per JavaScript im Browser zusammen. Leistungsfähige Crawler wie der Googlebot rendern die Seite deshalb wie ein echter Browser, um auch nachgeladene Inhalte zu sehen. Das ist aufwendig – viele kleinere Bots tun das gar nicht oder nur eingeschränkt.
- Indexierung. Erst jetzt wird der aufbereitete Inhalt analysiert, bewertet und in den Index aufgenommen – eine riesige, durchsuchbare Datenbank. Crawling ist nur das Einsammeln; die Indexierung entscheidet, ob und wofür eine Seite überhaupt ausgespielt werden kann.
Zwei Begriffe sind dabei für die Praxis entscheidend:
- Crawl-Budget. Kein Bot crawlt unendlich. Pro Website steht ein begrenztes Kontingent an Abrufen zur Verfügung. Langsame Server, endlose Filter-URLs, Duplicate Content oder kaputte Links verbrennen dieses Budget – dann bleiben wichtige Seiten ungecrawlt.
- Crawl-Frequenz. Wie oft ein Bot wiederkommt, hängt davon ab, wie häufig sich Ihre Inhalte ändern und wie wichtig die Seite eingeschätzt wird. Eine tagesaktuell gepflegte Seite wird öfter besucht als ein statisches Impressum.
Wichtig: Neben den klassischen Suchmaschinen-Bots (Googlebot, Bingbot) sind längst eigene KI-Crawler unterwegs, die Inhalte für KI-Systeme einsammeln – etwa GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot, Google-Extended und CCBot (Common Crawl). Über die robots.txt können Sie diesen Bots gezielt erlauben oder verbieten, Ihre Inhalte für Training und Antworten zu nutzen. Wer hier pauschal alles aussperrt, ist morgen aus den KI-Antworten verschwunden – wer alles offenlässt, gibt seine Inhalte unkontrolliert frei. Hier braucht es eine bewusste Entscheidung.
2. Echtzeit-Abfrage durch KI: RAG statt „RAP“
Kommen wir zu dem Mechanismus, der oft – verständlicherweise – mit dem falschen Namen belegt wird. Wenn Sie ChatGPT, Perplexity oder Google AI eine aktuelle Frage stellen und eine Antwort mit Quellenangaben und Links bekommen, dann hat das Modell nicht aus dem Gedächtnis geantwortet. Es hat in diesem Moment im Web nachgeschaut. Dieses Verfahren heißt RAG – Retrieval-Augmented Generation, also „abruf-gestützte Generierung“. So läuft es ab:
- Anfrage verstehen. Die KI wandelt Ihre Frage in eine oder mehrere Suchanfragen um – oft präziser und umformuliert, manchmal in mehreren Varianten parallel.
- Retrieval (Abruf). Über eine Suchmaschine oder einen eigenen Index findet das System passende Quellen und ruft die betreffenden Seiten live ab. Genau hier wird Ihre Seite in Echtzeit geladen – das ist der Vorgang, den Sie als „Echtzeit-Abfrage“ beschrieben haben.
- Zerlegen & Einbetten (Chunking & Embeddings). Die abgerufenen Texte werden in kleine Sinnabschnitte („Chunks“) zerlegt und in Vektoren umgewandelt – mathematische Repräsentationen der Bedeutung. So kann das System blitzschnell die Passagen finden, die zur Frage am besten passen.
- Kontext zusammenstellen. Die relevantesten Passagen werden in das Kontextfenster des Sprachmodells geladen – quasi als Spickzettel, den das Modell beim Antworten direkt vor Augen hat.
- Generierung mit Quellen. Erst jetzt formuliert das Modell die Antwort – auf Basis der frisch abgerufenen Passagen – und verlinkt die genutzten Quellen.
Der entscheidende Unterschied zum Training: Bei RAG fließt Ihr Inhalt nicht dauerhaft ins Modell ein. Er wird für genau diese eine Antwort herangezogen und danach wieder „vergessen“. Der große Vorteil von RAG ist Aktualität: Das Modell kann über tagesaktuelle Ereignisse sprechen, obwohl sein Trainingswissen Monate alt ist. Und es reduziert sogenannte Halluzinationen, weil die Antwort an konkrete, nachprüfbare Quellen gebunden ist.
Für Sie als Websitebetreiber heißt das: Damit Ihre Inhalte überhaupt für RAG infrage kommen, müssen sie (a) crawlbar sein, (b) zu konkreten Fragen klare, gut abgrenzbare Antworten liefern und (c) in den zugrunde liegenden Suchindizes auftauchen. Klar strukturierte Abschnitte, eindeutige Definitionen, Zahlen und FAQ-Blöcke sind exakt das Material, aus dem RAG-Antworten gebaut werden. Genau hier setzt Generative Engine Optimization (GEO) an.
3. Wie wird eine KI trainiert?
Der dritte Mechanismus ist das Training – der Vorgang, durch den ein Sprachmodell wie GPT, Claude oder Gemini überhaupt erst entsteht. Das passiert nicht laufend, sondern in großen, abgeschlossenen Trainingsläufen. Stark vereinfacht in vier Phasen:
- Datensammlung. Die Grundlage ist ein gigantischer Textkorpus aus dem öffentlichen Web (oft über Crawls wie Common Crawl), aus Büchern, Code, Foren und lizenzierten Datenquellen. Hier schließt sich der Kreis zum Crawling: Was Bots einsammeln durften, kann Teil der Trainingsdaten werden.
- Pre-Training. Das eigentliche Lernen. Der Text wird in kleine Einheiten zerlegt (Tokens), und das Modell lernt über Milliarden von Beispielen, das jeweils nächste Token vorherzusagen. Aus diesem schlichten Prinzip – „Was kommt als Nächstes?“ – entstehen über Milliarden bis Billionen von Parametern erstaunliche Sprach- und Faktenfähigkeiten. Dieser Schritt kostet enorme Rechenleistung und dauert Wochen bis Monate.
- Feintuning (Fine-Tuning). Das rohe Modell wird auf konkrete Aufgaben und gewünschtes Verhalten nachgeschärft – etwa darauf, hilfreiche Antworten zu geben, Anweisungen zu folgen und ein bestimmtes Format einzuhalten.
- Ausrichtung per Feedback (RLHF). In der Phase „Reinforcement Learning from Human Feedback“ bewerten Menschen Antworten, und das Modell lernt, welche Antworten als hilfreich, sicher und korrekt gelten. So wird aus einem reinen Textvorhersager ein brauchbarer Assistent.
Zwei Dinge sind hier zentral zu verstehen:
- Knowledge-Cutoff. Ein trainiertes Modell „kennt“ die Welt nur bis zu einem bestimmten Stichtag – dem Datenstand des Trainings. Alles danach weiß es nur, wenn es per RAG live nachschaut. Deshalb ergänzen sich Training und RAG: Das eine liefert das Grundverständnis, das andere die Aktualität.
- Keine 1:1-Speicherung. Ein Modell legt Ihre Texte nicht als Kopie ab. Es lernt statistische Muster. Tauchen Ihre Inhalte, Ihre Marke und Ihre Aussagen aber häufig und konsistent im Trainingsmaterial auf, steigt die Wahrscheinlichkeit, dass das Modell sie „verinnerlicht“ und später von sich aus erwähnt.
Was bedeutet das alles für Ihre Website?
Die gute Nachricht: Alle drei Mechanismen belohnen im Kern dasselbe – technisch sauber zugängliche, inhaltlich klare und vertrauenswürdige Websites. Diese Hebel zahlen auf alle drei gleichzeitig ein:
- Crawlbarkeit sicherstellen. Schnelle Ladezeiten, eine saubere Seitenstruktur, eine gepflegte
robots.txtund eine aktuelle XML-Sitemap. Was nicht gecrawlt werden kann, taucht weder im Index noch in KI-Antworten auf. - KI-Crawler bewusst steuern. Entscheiden Sie aktiv, welche KI-Bots (
GPTBot,ClaudeBot,PerplexityBot,Google-Extended& Co.) Ihre Inhalte nutzen dürfen – statt es dem Zufall zu überlassen. - Inhalte „antwortfähig“ schreiben. Klare Definitionen am Anfang, präzise Zahlen, eindeutige Aussagen, FAQ-Blöcke und Tabellen. Das ist genau das Material, das RAG-Systeme zitieren.
- Struktur für Maschinen mitliefern. Strukturierte Daten (Schema.org) und eine
llms.txthelfen Maschinen, Ihre wichtigsten Inhalte sauber zu erfassen. Wie eine llms.txt aufgebaut sein muss, haben wir hier ausführlich erklärt. - Autorität und Vertrauen aufbauen. Autorennennungen, Quellen, Aktualisierungsdaten, eigene Daten und Studien. Konsistente, glaubwürdige Inhalte werden häufiger zitiert – in der Suche wie in der KI (Stichwort E-E-A-T).
Fazit: Drei Mechanismen, eine Strategie
Crawling, RAG und Training sind drei verschiedene Türen zu Ihren Inhalten – aber sie führen alle in denselben Raum. Das Crawling sammelt ein, was im Web steht. RAG ruft Ihre Seiten in Echtzeit ab, um aktuelle Fragen zu beantworten. Und das Training formt aus Milliarden von Texten das Grundwissen der Modelle. Wer alle drei versteht, sieht klar: Es gibt keine getrennten Welten von „SEO hier“ und „KI dort“. Es gibt nur eine Frage – ist Ihre Website technisch zugänglich, inhaltlich klar und als Quelle vertrauenswürdig genug, dass Maschinen sie finden, verstehen und zitieren?
Wenn Sie wissen wollen, wie gut Ihre Website heute für Crawler und KI-Systeme aufgestellt ist – und wo die größten Hebel liegen: Wir prüfen Ihre KI-Sichtbarkeit, leiten daraus eine konkrete GEO-Strategie ab und verzahnen sie mit Ihrer bestehenden SEO-Roadmap. Damit Ihre Marke in der Google-Suche und in der KI-Antwort gefunden wird.